Simulating Human Behavior with AI Agents - Stanford HAI

TL;DR
- Stanford's AI agents replicate human behavior with 85% statistical accuracy.
- Digital Twins replace static marketing personas with dynamic, data-driven simulations.
- Researchers use qualitative interview data to model specific individual biases.
- In Silico testing allows for rapid stress-testing of ideas in digital sandboxes.
- AI simulacrums now mimic human memory, quirks, and linguistic patterns.
Simulating Human Behavior with AI: Inside Stanford’s "Digital Twin" Breakthrough
We have stopped asking AI to simply write like a human. That trick is old news. We are now asking it to behave like a specific one.
The era of the "Chatbot" is dead. The era of the "Simulacrum" has arrived.
Researchers at Stanford have successfully engineered generative agents that don't just mimic general human speech patterns—they replicate the specific attitudes, biases, quirks, and survey responses of real, living individuals. And they do it with 85% accuracy.
Let that sink in. This isn't a sci-fi projection for the next decade. It is a statistical benchmark available right now. That 85% match rate is roughly the same consistency you’d get if you asked a real human to retake a test two weeks later. Humans change their minds; these agents change them in the exact same way.
While synthetic users will never fully replace the chaotic, beautiful mess of organic human feedback, the 2026 standard for high-level research is undeniable: "In Silico" testing. We are moving toward a workflow where we stress-test ideas in a digital sandbox—running thousands of simulated years in an afternoon—before they ever touch a real person.
As detailed in the Stanford HAI Policy Brief, this architectural breakthrough allows us to simulate human behavior with a precision that makes traditional "user personas" look like stick figure drawings.
From "Marketing Personas" to "Digital Twins"
For decades, UX directors and brand strategists have relied on the "User Persona." You know the drill. You walk into a conference room and see a slide introducing "Accountant Andy."
Andy is 35. He "likes efficiency." He "hates clutter." He drives a sedan.
These personas are useful, sure. But let’s be honest: they are creative writing exercises. They are fiction based on aggregate assumptions. They are static. They do not react. They just sit there on a PDF, smiling a stock-photo smile, while your product team argues over what Andy might do.
Digital Twins are a different beast entirely.
A Digital Twin isn't built on general demographics. It is grounded in specific, qualitative data—often derived from over two hours of intense interview transcripts per agent. According to NN/g’s analysis on AI-simulated behavior, the distinction lies in the fidelity of the source material.
A Digital Twin doesn't just answer a question. It answers it with the specific linguistic ticks, memory biases, and irrational preferences of the actual human it models.
Think of it as the "Shibboleth" rule. A generic AI can tell you what an accountant might say about tax software. A Digital Twin can tell you what this specific accountant would say when they are tired, frustrated with a clunky UI, and thinking about their lunch. It preserves the "noise" of human behavior that standard marketing personas meticulously scrub out.
If "Accountant Andy" is a sketch, a Digital Twin is a high-definition hologram that argues back.
The "Goldfish Problem": Why Standard LLMs Fail
The skeptics are right about one thing: a standard Large Language Model (LLM) cannot do this.
If you fire up ChatGPT and ask it to "act like a 35-year-old," it relies on stereotypes. It hallucinates a caricature. Worse, it has the memory of a goldfish. It has a limited context window. It forgets who it is the moment the conversation drifts too far. It cannot maintain a personality over time because it has no continuity.
Stanford solved this by engineering a "brain" capable of continuity. They didn't just prompt an LLM; they built a wrapper around it. As outlined in the seminal paper Generative Agents: Interactive Simulacra of Human Behavior, the magic happens in three distinct components that mimic human cognition:
- Memory Stream: This is the agent's database. But it’s not just a log of "User said X." It is a searchable history of experiences.
- Reflection: This is the game-changer. The agent doesn't just react; it pauses. It synthesizes memories into high-level inferences. It realizes, "I am usually impatient with slow loading screens," and stores that as a personality trait. It learns about itself.
- Planning: The agent anticipates future actions based on these past patterns.
It is a cyclical process of perception, retrieval, and action.
This architecture allows the agent to retrieve memories not just by what happened last, but by what is relevant and important to the current context.
If a simulated agent burns its toast in the morning (recorded in the Memory Stream), and you ask it to test a toaster interface three hours later, it will be "annoyed." That is the spark of life in the machine.
Validating the Simulation: The "1,052 Individuals" Study
Anyone can build a bot and claim it's "lifelike." Being lifelike is easy. Being accurate is hard.
The claim of "simulation" is worthless without validation. Stanford didn't just build a few bots; they conducted a massive validation study involving 1,052 real individuals.
The methodology was rigorous. The researchers interviewed these people, built agents based on their transcripts, and then had both the humans and the agents take the General Social Survey (GSS)—a gold-standard sociological tool used to track American attitudes since 1972.
The results were startling. The agents replicated the attitude of their human counterparts with 85% accuracy. But the most interesting finding was something called the Bias Paradox.
Common wisdom suggests AI is inherently biased. We assume it amplifies the stereotypes found in its training data—that it will make nurses female and doctors male, or make assumptions based on race.
However, Stanford found the opposite happens when you get specific.
When you ground an agent in specific, individual interview data, it actually reduces stereotypical racial and ideological biases compared to generic "steered" personas.
Why? Because stereotypes are fillers for missing information. When the AI is forced to be "John, the 40-year-old mechanic from Ohio" based on John's actual words, it stops relying on the caricature of a "mechanic." It starts behaving like John. John might hate cars. John might love opera. John is a person, not a statistic.
Specificity, it turns out, is the antidote to stereotype.
The 2026 Workflow: Introducing the "Research Sandwich"
The immediate fear from UX teams is predictable. I hear it in every boardroom: "Does this replace user testing? Are we firing the researchers?"
No. Put the pitchforks down.
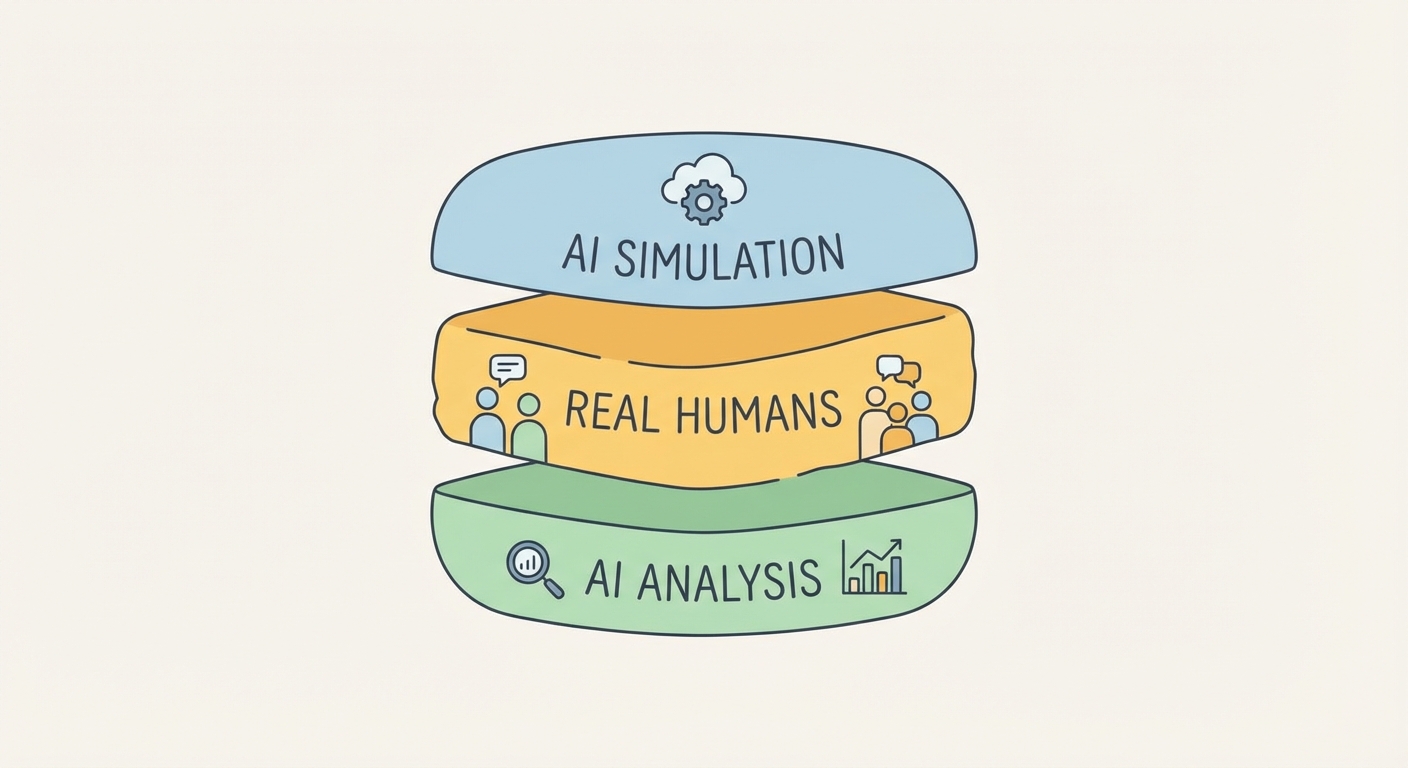
If you replace real humans entirely, you are building a hallucination loop. You are designing software for ghosts. The 2026 industry standard is not replacement; it is the "Research Sandwich."
This hybrid model leverages the speed of silicon and the truth of biology. If you are looking to modernize your user research methods, this is the blueprint you need to tape to your wall:
- Top Slice (Synthetic): You start with Digital Twins. You run 1,000+ iterations of a user flow to debug logic, find dead ends, and stress-test the architecture. This is "In Silico" testing. It’s cheap, fast, and ruthless at finding functional flaws. You can simulate a year of traffic in an hour. You catch the obvious bugs that would annoy a real human.
- The Meat (Organic): Once the logic is solid, you bring in Real Humans. This is the non-negotiable center. You test for emotional resonance, desirability, and the "unknown unknowns." You test for the physical constraints—the thumb that can't reach the button, the glare on the screen, the bad mood caused by a rainy Tuesday. This is where you find the truth.
- Bottom Slice (AI Synthesis): Finally, you use AI to analyze the delta between what the Digital Twins predicted and what the Real Humans actually did. That gap is your insight. Why did the humans hesitate where the bots didn't?
Beyond UX: The Rise of "In Silico" Social Science
The implications extend far beyond fixing a checkout flow or making a better "Add to Cart" button. We are witnessing the rise of "In Silico" Social Science.
Economists and public health officials are beginning to use these agents for high-stakes testing. Imagine you need to roll out a new public health message about vaccines to a small town. Historically, you launch the campaign and hope for the best. If you fail, you fail in public, at great cost.
Now, imagine testing that message on a simulated population of that specific town before spending millions on ad buys. You can predict resistance. You can spot where the misunderstanding happens. You can see adoption rates ripple through the digital twin community without risking a single real-world failure.
Furthermore, the technology is becoming vision-aware. By late 2026, we expect agents that can "see" screens and moderate sessions, adding a layer of observational data to the mix. Companies navigating this shift often require specialized AI consulting services to build the infrastructure capable of running these massive simulations.
The Ethics of Simulation: Deepfakes and Consent
We need to talk about the elephant in the server room. With great simulation comes a terrifying potential for abuse.
The ability to create a digital twin of a person is effectively identity theft via simulation. If I can simulate your behavior perfectly, I can manipulate you. Worse, I can simulate your consent. I can ask your digital twin if it wants to buy a product, get a "yes," and use that as justification to target the real you.
Stanford addressed this with strict "Kill Switch" protocols. The agents are hard-coded to refuse harmful tasks and, crucially, are often anonymized in deployment. But let’s be real: as this moves from the safety of academia to the open market, the guardrails will get flimsy.
Companies need a robust Data Ethics Framework before they write the first line of code. You must ask the hard questions:
- Do we have consent to simulate these individuals?
- Who owns the "digital twin"—the company or the human it mimics?
- What happens when the twin reveals something the human wanted to keep private?
The risk of "deepfake behavior" is real. The legal landscape is still catching up, but the moral obligation is already here.
Conclusion
Generative agents are a mirror, not a replacement.
They allow us to test the probable so we can focus human time on the possible. They clear the brush so researchers can focus on the trees. They take the grunt work out of validation so we can focus on the empathy.
The technology is not waiting for permission. It is here. The question is not whether you will use simulated users, but whether you will use them to enhance your understanding of humanity or to obscure it.
Start by building your first "In Silico" control group. Test your assumptions against the machine, so you can bring a better reality to the humans.
FAQ Section
1. Can AI agents replace real human user testing? No. As of the 2026 industry standard, experts recommend a "Research Sandwich" approach. AI agents are used for "debugging" logic, stress-testing workflows, and predicting behavior at scale ("In Silico" testing). However, real humans are still required to validate emotional desirability and unforeseen physical constraints.
2. How accurate are Stanford's generative agents? Stanford’s study showed that generative agents achieved 85% accuracy in replicating the survey responses of the specific individuals they were modeled after. This statistical consistency is comparable to the rate of a real human retaking the same survey two weeks later.
3. What is the difference between a Synthetic User and a Digital Twin? A Synthetic User is typically a generic persona based on aggregate demographic data (e.g., "A 30-year-old urban professional"). A Digital Twin, as defined by Stanford HAI, is an agent trained on the specific qualitative data (interviews, writing history) of a real, living individual, allowing it to mimic specific biases and memory patterns.
4. How do generative agents "remember" past interactions? Unlike standard chatbots, generative agents utilize a unique architecture involving a "Memory Stream." This is a database of experiences that the agent retrieves based on three factors: Recency (how long ago it happened), Importance (emotional weight), and Relevance (connection to the current context).



